Round Robin Load Balancing: When Simple Distribution Costs You Performance

Round robin load balancing distributes requests sequentially across available servers—a dead-simple strategy that works brilliantly until it doesn’t. For technical teams evaluating proxy infrastructure, the core question isn’t whether round robin is “good” or “bad,” but whether its operational tradeoffs align with your fleet’s reality. This approach excels when servers have identical capacity and workloads are predictable, delivering effortless implementation and minimal overhead. It falters when backend resources vary in performance, request complexity differs dramatically, or server health changes mid-operation. The strategic decision hinges on specific factors: your infrastructure’s uniformity, traffic patterns, monitoring capabilities, and tolerance for occasional inefficiency. Understanding where round robin’s elegant simplicity becomes a liability—and which scenarios demand weighted algorithms, least-connection routing, or health-aware distribution—determines whether you’re optimizing for operational ease or maximum performance. This analysis maps the concrete advantages, hidden costs, and decision criteria that separate appropriate deployments from architectural mismatches.
How Round Robin Works in Proxy Fleet Routing
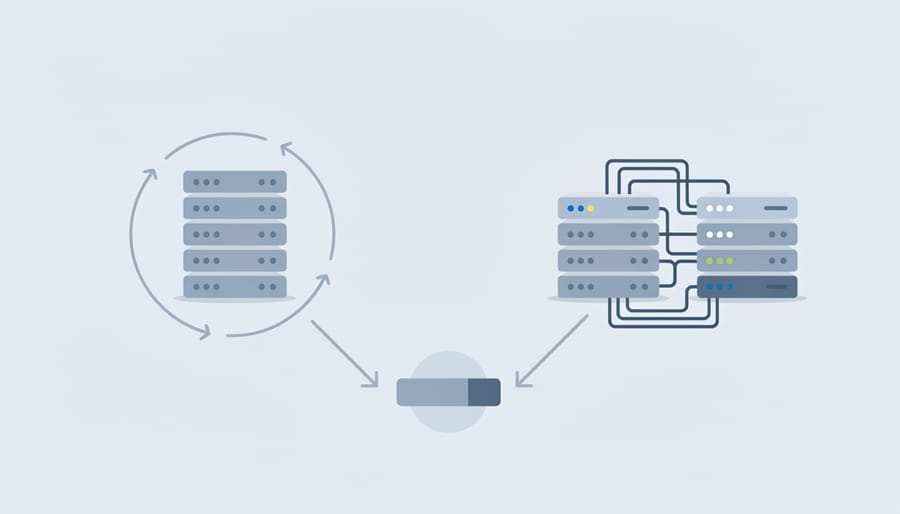
Round robin distributes requests across proxies using a fixed, repeating sequence—no measuring, no thinking, just 1-2-3-4-1-2-3-4. When a request arrives, the router assigns it to the next proxy in line, advances the counter, and repeats indefinitely. Think of it as a mechanical turnstile: each visitor gets the next number regardless of who they are or what they need.
The mechanism operates without feedback loops. Proxy three might be timing out in Mumbai while proxy one sits idle, but round robin keeps sending every third request to three anyway. It doesn’t check response times, track error rates, or adapt to changing conditions. The algorithm maintains only a single integer—the current position—making it trivial to implement and debug.
Visualize four proxy servers arranged in a circle, with an arrow rotating clockwise after each assignment. Request A goes to proxy 1, arrow advances. Request B goes to proxy 2, arrow advances. Request C goes to proxy 3, and so on. The pattern never deviates based on geography, server health, or request complexity.
This simplicity creates both its greatest strength and its fundamental limitation. No computational overhead means millisecond-level decisions, but no intelligence means no optimization. The router treats a healthy Tokyo proxy with 10ms latency identically to a degraded London proxy crawling at 3000ms.

The Case for Round Robin: Why It’s the Default
Zero Overhead Implementation
Round robin requires no health monitoring daemon, no heartbeat protocol, no database of server states. You configure a list of backend addresses, and distribution begins immediately—no warm-up period, no metric collection lag, no complex decision trees evaluating response times or CPU loads. This architectural simplicity translates directly to reduced operational overhead: fewer moving parts to configure, debug, or scale as your proxy fleet grows.
The algorithm itself consumes negligible CPU cycles—just incrementing a counter and performing modulo arithmetic. No statistical analysis, no weighted probability calculations, no live performance profiling of downstream servers. For organizations running large proxy pools where request distribution speed matters and backend servers are genuinely equivalent, this zero-overhead approach eliminates an entire category of infrastructure complexity while maintaining predictable, deterministic behavior that’s trivial to reason about during incident response.
Predictable Resource Distribution
Round robin distributes traffic evenly across all proxies in your pool—each server receives an equal share regardless of performance characteristics. This predictability simplifies capacity planning: if you operate 100 proxies under round robin, each handles roughly 1% of total requests. Finance teams appreciate the straightforward cost allocation, since resource consumption maps directly to fleet size. Operations teams can forecast bandwidth and compute needs with confidence, making optimizing proxy fleet costs more transparent. This deterministic behavior shines when proxies are homogeneous—same specs, same providers, same geographic distribution. However, equal distribution assumes equal capability. If servers differ in speed, reliability, or network conditions, round robin’s fairness becomes a liability, sending identical loads to mismatched resources and degrading overall performance.
Perfect for Homogeneous Fleets
Round robin shines when your proxy fleet is truly uniform. If every proxy shares identical bandwidth, processing power, geographic location, and rate limits, round robin distributes requests evenly without favoring any single node. This predictability simplifies capacity planning—you know exactly how many requests each proxy handles over time.
The approach works best in controlled environments where you provision infrastructure deliberately. Cloud-based proxy pools with standardized VM instances, identical ISP connections, and synchronized rate limit quotas are ideal candidates. No proxy becomes a bottleneck simply because the algorithm doesn’t account for real-world differences that don’t exist.
However, this sweet spot is narrower than it appears. Even minor variations—one proxy with slightly higher latency, another throttled by its provider—disrupt the fairness assumption. Round robin continues rotating blindly, sending equal traffic to unequal resources. For homogeneous fleets, it delivers elegant simplicity. For everything else, performance monitoring becomes essential to spot when uniformity breaks down and smarter routing becomes necessary.
Where Round Robin Breaks Down
No Awareness of Proxy Health or Performance
Round robin distributes requests mechanically without checking whether proxies are actually healthy or performing well. If a proxy becomes throttled, rate-limited, or starts returning errors, the algorithm continues sending traffic to it in rotation. This creates a cascade: requests hit the degraded proxy, time out or fail, then retry logic kicks in—wasting time and resources while users wait. Without proxy health monitoring, you won’t know which proxies are dragging down overall performance until failures become obvious through customer complaints or manual log analysis. The longer a failing proxy stays in rotation, the more requests it corrupts. In production environments handling thousands of requests daily, even one consistently slow proxy in a ten-proxy pool wastes 10% of your capacity and degrades latency percentiles. Manual intervention becomes the only remedy—pulling problematic proxies requires someone to notice, investigate, and reconfigure routing rules.

Ignores Geographic and Network Latency
Round robin treats all backend servers identically regardless of physical location or network conditions. A proxy 20 milliseconds away receives the same traffic share as one 400 milliseconds distant. This geography-blind distribution degrades user experience—requests routed to far endpoints wait longer while nearby capacity sits underutilized. The algorithm cannot detect that one datacenter responds in 50ms while another takes 800ms due to transcontinental latency. Users experience inconsistent page loads: fast on one request, sluggish on the next. High-performance proxies deliver no advantage because slow ones receive equal allocation. For globally distributed fleets or mixed-region infrastructure, this ignorance wastes your fastest resources and frustrates users who expect consistent speed. Latency-aware routing becomes essential when geography matters to your service quality.
Can’t Handle Rate Limits or Proxy-Specific Restrictions
Round robin treats all proxies identically, continuing to route traffic even after a specific IP encounters rate limits, temporary bans, or CAPTCHA challenges. When a proxy fails due to these restrictions, round robin simply cycles it back into rotation on its next turn, generating predictable 429 errors or blocked responses. This blind distribution means failed requests accumulate until manual intervention removes the problematic proxy. For fleets handling API-heavy workloads or scraping at scale, this lack of awareness creates cascading failures across your request queue. Unlike advanced routing algorithms that detect failure patterns and automatically quarantine unhealthy endpoints, round robin requires external monitoring to identify and address proxy-specific restrictions before they compromise throughput.
Poor Handling of Long-Lived Connections
Round robin distributes requests without tracking which server holds a user’s session state, forcing applications to either replicate session data across all backends or rely on sticky sessions—configurations that undermine the algorithm’s simplicity. Each new request from a long-lived client may land on a different server, multiplying authentication overhead and database queries. Connection pooling benefits evaporate when traffic scatters randomly rather than consolidating on fewer backends. This matters most for WebSocket applications, database connection pools, and authenticated API services where connection setup costs dominate. For: infrastructure engineers weighing stateful application requirements against routing complexity.
When to Use (and Skip) Round Robin
Ideal Use Cases
Round robin shines in three scenarios. First, when you’re running a small, homogeneous fleet where all backends have identical capacity and response characteristics—no need for complex health checks or weighted distribution. Second, in development and staging environments where simplicity accelerates iteration and debugging trumps optimization. Third, for non-critical workloads with forgiving latency requirements where occasional misrouting won’t trigger incidents. If your proxies are interchangeable, traffic patterns are predictable, and you value operational simplicity over sophisticated traffic shaping, round robin delivers adequate distribution with minimal configuration overhead. It falters when backend heterogeneity, performance variability, or mission-critical uptime demands smarter routing decisions.
When to Upgrade
Round robin works well for homogenous fleets under 10 servers handling similar request types, but watch for warning signs. If backend response times vary by more than 30%, or if memory-intensive tasks cause uneven resource consumption, switch to least-connections routing. When servers have different capacities—mixing VM sizes or hardware generations—weighted distribution prevents bottlenecks. Health check failures that persist beyond 60 seconds demand health-aware routing to avoid sending traffic to degraded nodes. Monitor queue depth and request latency percentiles: if P95 latency climbs while some backends idle, round robin’s blind rotation is costing you performance. Beyond 20-30 servers, or when handling mixed workloads like API calls and file uploads simultaneously, intelligent load balancing strategies become essential. The tipping point arrives when operational complexity from round robin’s limitations exceeds the simplicity it promised.
Round robin’s core tradeoff is stark: unmatched implementation simplicity versus limited intelligence under real-world fleet conditions. It distributes requests evenly without overhead, making it ideal for homogeneous proxy pools with predictable traffic. But it falters when servers vary in capacity, network conditions shift, or upstream targets impose rate limits, because it treats all backends identically regardless of their actual state.
Start simple. Deploy round robin for small, uniform fleets where monitoring shows consistent performance. As your infrastructure grows—adding geographic diversity, mixing proxy types, or handling varied workloads—instrument response times and error rates. When variance emerges, migrate incrementally toward weighted, least-connections, or health-aware strategies. The goal isn’t perfection from day one; it’s matching routing complexity to your operational reality.

